AI가 그림을 그린다는 게 이제 새로운 이야기는 아닙니다. 하지만 바이트댄스(ByteDance)가 이번에 들고 나온 기술은 조금 다릅니다. 단순히 더 좋은 이미지를 만드는 게 아니라, AI가 그림을 그리는 방식 자체를 바꿔버렸거든요.
이름하여 GRN(Generative Refinement Networks, 생성 정제 네트워크). 틱톡의 모회사로 우리에게 친숙한 바이트댄스의 상업화 기술팀이 개발한 이 모델은, 기존 AI 이미지·영상 생성 기술의 두 가지 주류 방식을 모두 뛰어넘는 ‘제3의 길’을 제시했습니다.
처음 이 소식을 접했을 때 솔직히 반신반의 했습니다.
AI 영상 생성 분야에서 “새로운 패러다임”이라는 말은 워낙 자주 나오다 보니 이제는 그냥 그런가 보다 하는 수준인데요, 그런데 실제 생성 결과물을 보고 나서는 생각이 달라졌습니다. 80년대 가족사진 스타일의 이미지, K-pop 그룹의 무대 영상, 복잡한 만화 스타일 일러스트까지 — 이 모든 게 단 하나의 모델에서 나왔다는 게 꽤 인상적이었습니다.
요즘 보면 바이트댄스가 이미지 영상 생성 등 AI 분야 기술력이 거의 탑인 거 같은데요, 요거는 어떤 내용인지 한번 살펴보도록 하겠습니다.

기존 AI 이미지 생성, 뭐가 문제였나?
GRN이 왜 등장했는지 이해하려면, 먼저 기존 기술의 한계를 알아야 합니다. 현재 AI 이미지·영상 생성 분야에는 크게 두 가지 주류 방식이 있습니다.
첫 번째: 확산 모델(Diffusion Model)

확산 모델은 현재 가장 널리 쓰이는 방식입니다. 스테이블 디퓨전(Stable Diffusion)이나 미드저니(Midjourney) 같은 서비스가 이 방식을 씁니다. 쉽게 말하면, 노이즈(잡음)가 가득한 이미지에서 출발해 조금씩 잡음을 제거하면서 최종 이미지를 완성하는 방식입니다.
문제는 이 방식이 “무조건 같은 수의 붓질”을 한다는 점입니다.
사과 하나를 그리든, 복잡한 바로크 양식의 벽화를 그리든 동일한 횟수의 연산 단계를 거칩니다. 효율적이지 않죠. 게다가 전체적인 맥락을 파악하는 능력이 부족합니다.
두 번째: 자기회귀 모델(Autoregressive Model)
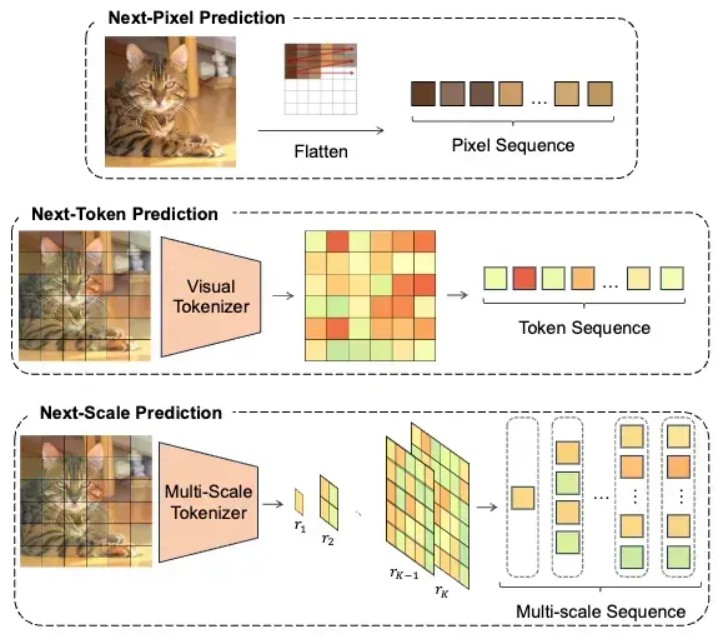
자기회귀 모델은 텍스트 생성 AI(ChatGPT 같은)와 비슷한 방식으로, 이미지를 작은 조각(토큰)으로 나눠 순서대로 하나씩 생성합니다. 이 방식은 이미지의 복잡도를 어느 정도 파악할 수 있다는 장점이 있습니다.
하지만 치명적인 단점이 있습니다. 지우개가 없다는 것입니다.
앞에서 한 번 잘못 그리면, 그 오류가 뒤로 계속 전파됩니다. 처음에 눈을 조금 이상하게 그렸다면, 그 이상한 눈을 기준으로 나머지 얼굴이 점점 더 이상하게 완성되는 식이죠. 또한 이미지를 이산적인 숫자 코드로 변환하는 과정에서 세밀한 디테일이 손실되는 문제도 있습니다.
GRN이 제시한 ‘제3의 길’이란?
바이트댄스의 GRN은 이 두 가지 방식의 단점을 동시에 해결하려는 시도입니다. 핵심 아이디어는 간단합니다.
“사람처럼 그리자”는 것입니다.
사람이 그림을 그릴 때를 생각해보세요. 처음에 대략적인 스케치를 하고, 잘못된 부분은 지우고 다시 그리고, 점점 세밀하게 다듬어 나갑니다. 복잡한 그림은 더 많은 시간을 들이고, 단순한 그림은 빠르게 끝냅니다. GRN이 바로 이 방식을 AI에 적용한 것입니다.
GRN의 핵심 구조는 세 가지 기술로 이루어져 있습니다.
1. 계층적 이진 트리 양자화(HBQ) — 정보 손실 없는 압축
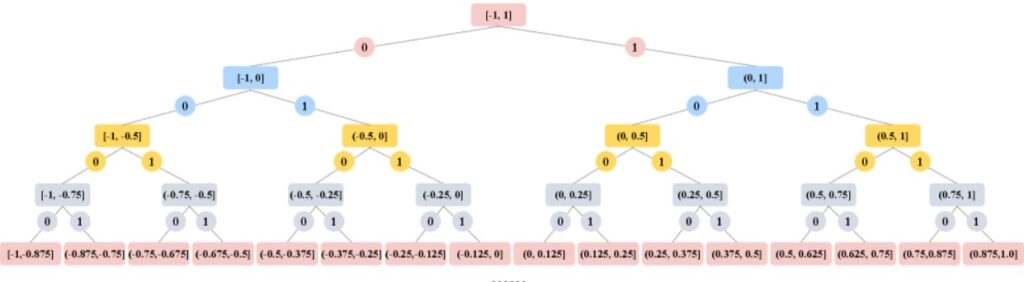
자기회귀 모델의 가장 큰 문제 중 하나는 이미지를 숫자 코드로 변환할 때 정보가 손실 된다는 점입니다. HBQ는 이를 해결하기 위해 이진 트리(Binary Tree) 구조를 활용합니다.
쉽게 말하면, 이미지 정보를 0과 1의 조합으로 매우 정밀하게 표현하는 방식인데, 압축 횟수가 늘어날수록 오차가 기하급수적으로 줄어들어 이론적으로는 완전 무손실 압축이 가능합니다. 실제 실험에서도 기존 방식(SD-VAE, rFID 0.87)보다 훨씬 낮은 rFID 0.56을 기록하며 이미지 재현 품질에서 압도적인 성능을 보였습니다.
2. 전역 정제 네트워크(GRN) — 지우개를 가진 AI

GRN의 가장 독창적인 부분입니다. 기존 자기회귀 모델은 한 번 생성한 토큰을 수정할 수 없었지만, GRN은 전체 이미지를 반복적으로 다듬는 과정을 도입했습니다.
처음에는 무작위 토큰(빈 캔버스)에서 시작합니다. 그런 다음 AI가 전체 맥락을 보면서 어떤 부분이 잘 그려졌고 어떤 부분이 아직 불완전한지 판단합니다. 잘 그려진 부분은 유지하고, 불완전한 부분은 다시 그립니다. 이 과정을 반복하면서 점점 완성도 높은 이미지가 만들어집니다. 심지어 이미 ‘완성’으로 표시된 부분도, 나중에 더 많은 맥락 정보가 쌓이면 더 나은 버전으로 교체될 수 있습니다.
연구팀은 이를 ‘토큰 정제(Token Refinement)’라고 부릅니다.
3. 복잡도 인식 샘플링 — 단순하면 빠르게, 복잡하면 꼼꼼하게
GRN은 엔트로피(Entropy)라는 개념을 활용해 이미지의 복잡도를 측정합니다. 엔트로피가 낮으면 단순한 이미지, 높으면 복잡한 이미지입니다. 이를 바탕으로 단순한 이미지에는 적은 연산 단계를, 복잡한 이미지에는 더 많은 단계를 자동으로 배분합니다.
실험 결과, 가장 작은 1억 3천만 개 파라미터(130M) 모델 기준으로 기존 50단계 연산이 평균 24단계로 줄었습니다. 품질 지표(gFID)는 3.56에서 3.79로 아주 소폭 상승하는 데 그쳤습니다. 효율성과 품질을 동시에 잡은 셈입니다.
GRN 실제 성능은 어느 수준인가?
논문 속 숫자만으로는 실감이 안 날 수 있으니, 실제 벤치마크 결과를 살펴보겠습니다.
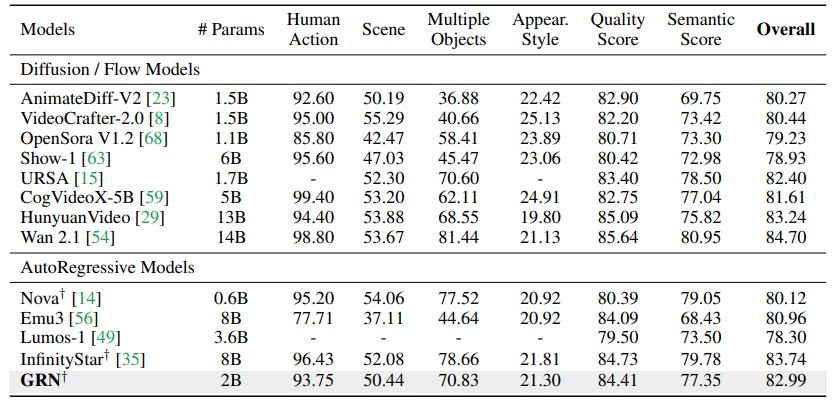
이미지 생성(C2I, 클래스→이미지) 분야에서 GRN-G(20억 파라미터) 모델은 FID 1.81, IS 299.0을 기록했습니다. FID는 낮을수록, IS는 높을수록 좋은 지표인데, 이 수치는 DiT-XL/2, VAR-d30, LlamaGen-XXL 등 현재 주류 생성 모델들을 모두 앞서는 결과입니다.
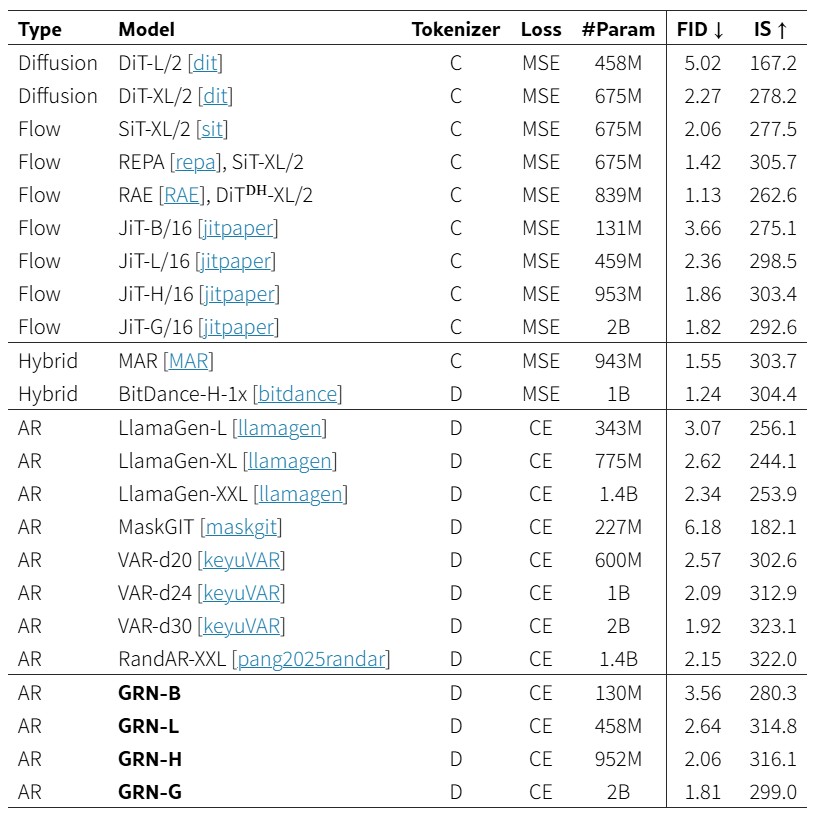
텍스트→이미지(T2I) 분야에서는 GRN_bit 2B 모델이 GenEval 벤치마크에서 0.76점을 기록, 같은 20억 파라미터 규모의 SD3 Medium과 Infinity를 넘어섰습니다. 60억~200억 파라미터급 대형 모델들에는 아직 미치지 못하지만, 연구팀은 언어 모델처럼 파라미터를 늘릴수록 성능이 잘 오르는 특성(Scaling)이 있다고 밝혔습니다. 더 큰 모델이 나올 경우 격차가 좁혀질 가능성이 충분합니다.
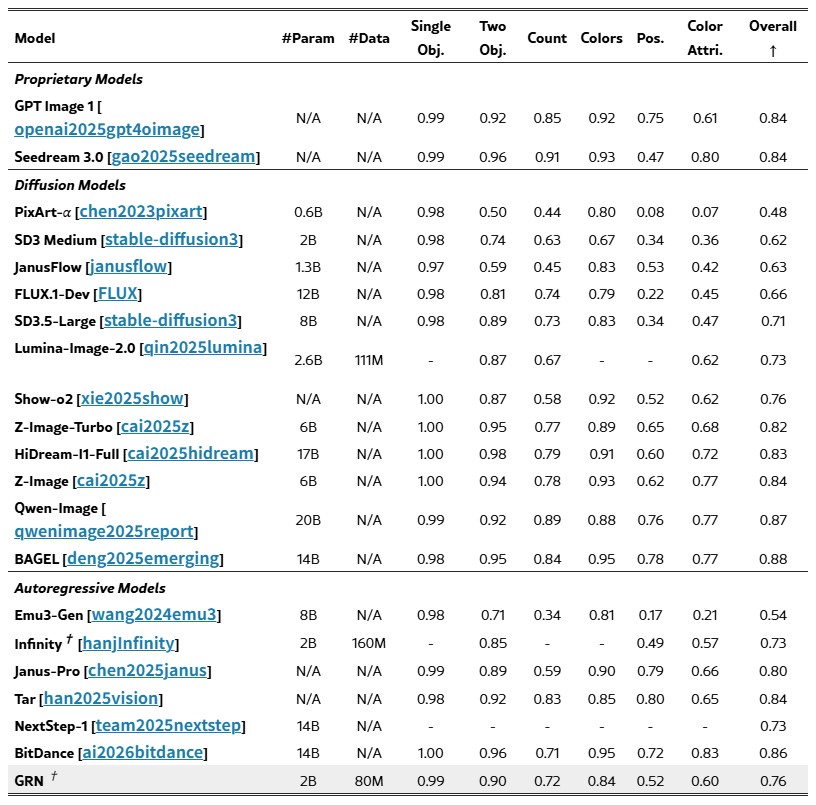
가장 눈에 띄는 건 텍스트→영상(T2V) 분야입니다. 20억 파라미터의 GRN 모델이 최대 480p 해상도, 2~10초 길이의 고품질 영상을 생성할 수 있는데, VBench 테스트에서 50억 파라미터의 CogVideoX와 무려 140억 파라미터의 Wan 2.1을 넘어섰습니다. 파라미터 수가 7배나 많은 모델을 2B짜리가 이긴 셈입니다. 이 부분은 솔직히 꽤 놀라운 결과입니다.
직접 써볼 수 있나? — 오픈소스 공개 현황
바이트댄스는 GRN을 오픈소스로 공개했습니다. 이미지 생성(T2I) 모델은 HuggingFace에서 바로 체험할 수 있고, 영상 생성(T2V) 2B 모델은 GitHub에 코드가 공개되어 있으며 Discord를 통한 데모도 제공됩니다.
HuggingFace 데모에서는 프롬프트(텍스트 명령어)의 연관성이나 창의적 발산 정도 같은 파라미터를 직접 조절해볼 수 있습니다. 80년대 생일 파티 가족사진을 생성해보면 CCD 필름 카메라 특유의 질감이 살아있고, 복잡한 만화 스타일 일러스트도 배색과 구도가 꽤 안정적으로 나옵니다.
영상 생성 쪽에서는 단일 인물의 간단한 장면은 물론, 여러 명이 등장하는 K-pop 무대 영상처럼 카메라가 빠르게 움직이는 복잡한 장면도 화면 왜곡 없이 생성된다는 점이 인상적입니다. 2B라는 비교적 작은 모델 크기를 감안하면 더욱 그렇습니다.
이 기술이 앞으로 어떤 의미를 가질까?
GRN이 단순히 성능 좋은 모델 하나를 내놓은 것 이상의 의미를 갖는 이유가 있습니다.
첫째, 이미지·영상·텍스트를 하나의 모델로 통합할 가능성을 열었습니다. GRN은 순수하게 이산 토큰(discrete token) 방식으로 이미지와 영상을 모두 처리합니다. 텍스트도 같은 방식으로 처리되기 때문에, 장기적으로는 하나의 모델이 텍스트·이미지·영상을 모두 이해하고 생성하는 진정한 멀티모달 AI로 발전할 수 있는 기반이 됩니다.
둘째, 연구팀은 GRN의 ‘전역 정제’ 아이디어를 텍스트 생성 AI(LLM)에도 적용할 수 있다고 제안합니다. 현재 ChatGPT 같은 언어 모델도 앞에서 잘못 생성한 내용을 뒤에서 수정하지 못하는 문제가 있는데, GRN 방식을 도입하면 텍스트 생성 후에도 앞부분을 다시 고칠 수 있는 가능성이 생깁니다.
셋째, 효율성의 문제입니다. 복잡도에 따라 연산량을 자동 조절하는 방식은 AI 서비스 운영 비용을 크게 낮출 수 있습니다. 상업적으로 매우 중요한 부분이죠.
참으로 요즘 AI 업계는 정말 매일매일이 전쟁터 같습니다. 이미지·영상 생성 AI 개발에 투자하고 있는 업체들은 바이트댄스처럼 기초 아키텍처 수준에서 새로운 방향을 제시하는 연구가 나오면 기존 기술 스택 전체를 재검토해야 하는 상황이 올 수도 있습니다. 단순히 모델 성능 경쟁이 아니라, 패러다임 자체가 바뀌는 것이기 때문입니다.
바이트댄스는 틱톡이라는 플랫폼을 통해 전 세계 수억 명의 영상 데이터를 보유하고 있습니다. 여기에 GRN 같은 기초 기술 연구까지 더해진다면, 영상 생성 AI 분야에서의 영향력은 앞으로 더 커질 가능성이 높습니다. 기술의 발전 속도와 방향을 냉정하게 지켜볼 필요가 있는 이유입니다.
논문과 코드는 모두 공개되어 있으니, 관심 있는 분들은 직접 확인해보시는 것도 좋을 것 같습니다.
📄 논문 : https://arxiv.org/abs/2604.13030
💻 코드 : https://github.com/MGenAI/GRN
🤗 HuggingFace 데모 : https://huggingface.co/spaces/hanjian/GRN
🌐 프로젝트 페이지 : https://mgenai.github.io/GRN/






